|

Platinum
Classify New Data
Overview
Classification is the process of using a trained classifier to predict the classes of the items in a dataset.
If you use an ANN or SVM Classifier, the dataset to be classified must have the same genes as the training dataset, in the same order and without any extra genes.
If you use an IBIS classifier, the dataset must contain the gene or gene pair used to create the IBIS classifier.
Actions
1. Click a raw or filtered dataset in the Experiments navigator. The item is highlighted.
2. Click the Classify
toolbar icon ![]() , or select Classify
from the Predict menu. The Classify dialog is displayed.
, or select Classify
from the Predict menu. The Classify dialog is displayed.
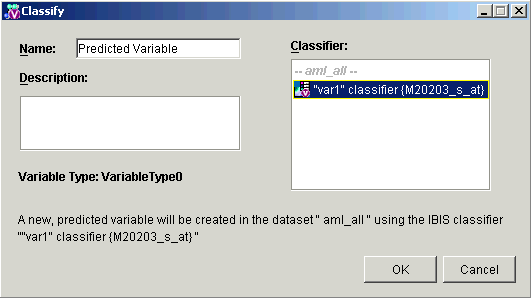
3. Set the parameters.
|
Parameter |
Description |
|
Name |
The name of the new item which will be seen in the Experiments navigator. |
|
Description |
An optional description of the item. |
|
Classifier |
The classifier to be used for the class prediction. |
4. Click OK. The Experiment Progress dialog is displayed. It is dynamically updated as the Classify operation is performed. To cancel the Classify operation, click the Cancel button.
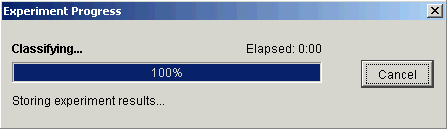
Upon successful completion, a new item (Name) is added under the original item in the Experiments navigator.
Reasons For Misclassifications:
There are often no misclassifications in the training data – artificial neural networks are fairly powerful and adaptable learners. If there are misclassifications, however, it may be for one of several possible reasons:
We may be using a set of genes which do not discriminate between the sample classes.
The training set may be unbalanced. That is, it may have too many examples of one class and not enough of another.
We may have set the number of hidden units in the neural networks too small.
The data may contain errors such as mislabelled samples or incorrect measurements.
The voting threshold may be set too low.
The stopping criteria may have been set too loose (maximum iterations too small).
The above reasons may affect either training or test results. If the training results are excellent but the test results are poor, it may be for one of the following additional reasons:
We may have set the number of hidden units in the neural networks too large.
We may have too many features (genes) for the number of samples in the training set.
The test data may be drawn from a significantly different population than the training data.
The test data may not have been normalized in a similar fashion to the training data.
The test dataset may have been filtered with different genes than the training dataset. (GeneLinker™ checks only that the number of genes used in training and prediction is the same, not their identities).
The stopping criteria may have been set too tight (maximum iterations too large).
Related Topics:
ANN Classification and Prediction Overview